Implementing an OCR process in Power Automate
Dustin Miner
- posted on
- Comments Off on Implementing an OCR process in Power Automate
Consider a scenario where a customer document (containing a cover page) has been scanned into a PDF and emailed to a company for processing. When the email is received, the cover page in the PDF is OCR’d and these details, along with the PDF, are stored in a SharePoint folder called ‘OCR Document Staging’.

(Please note that it’s assumed that the scanned PDF that is attached to the inbound email doesn’t already contain an OCR layer. That is, the contents of the PDF aren’t searchable.)
The Power Automate solution for this scenario is as follows:
The first Power Automate flow triggers on an email being received. It then iterates through the email attachments and stores the relevant PDF attachment in the SharePoint folder ‘OCR DropBox Documents’.
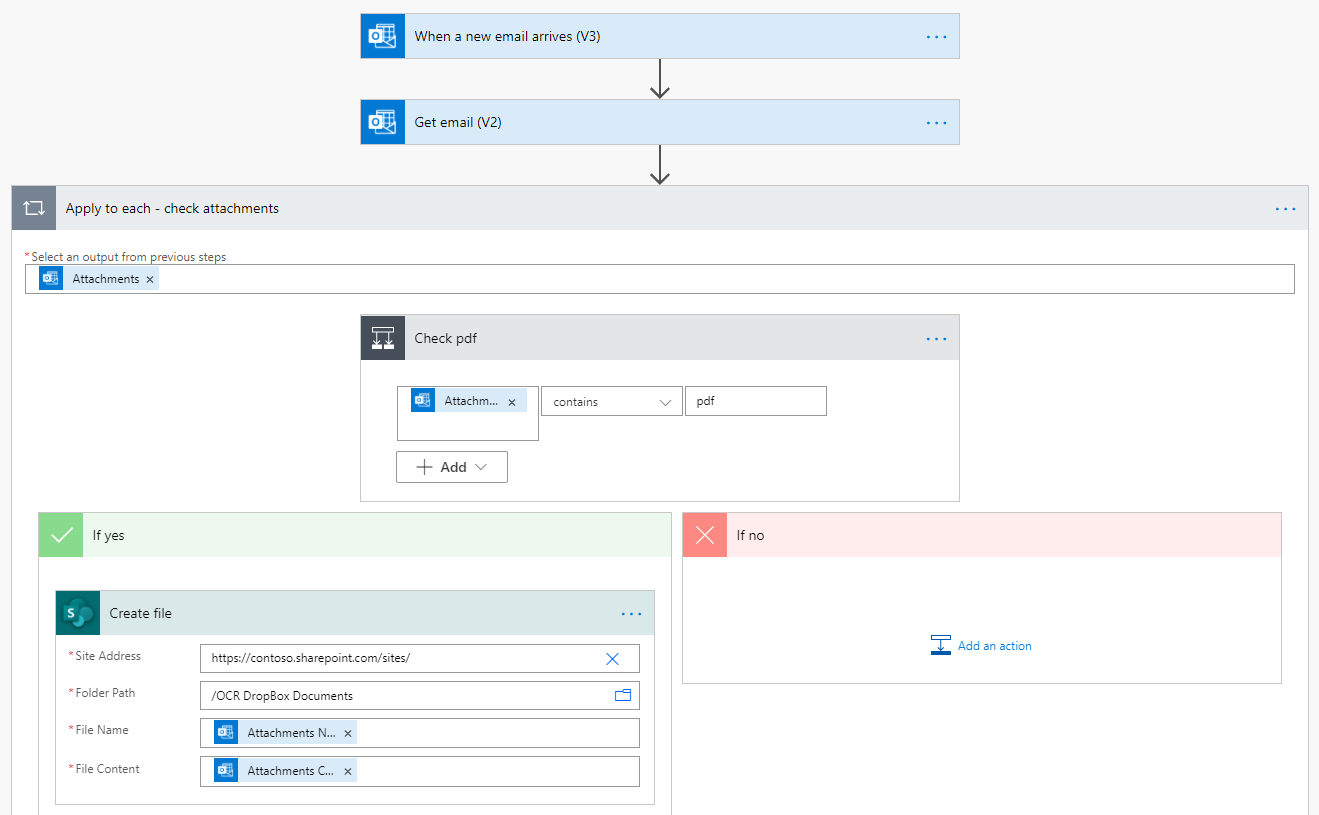
The result is the extracted PDF stored in the SharePoint folder:

The second Power Automate flow then triggers with the following steps being executed:
1.) The Aquaforest action ‘Get PDF properties’ is used to verify that the PDF is not already indexed
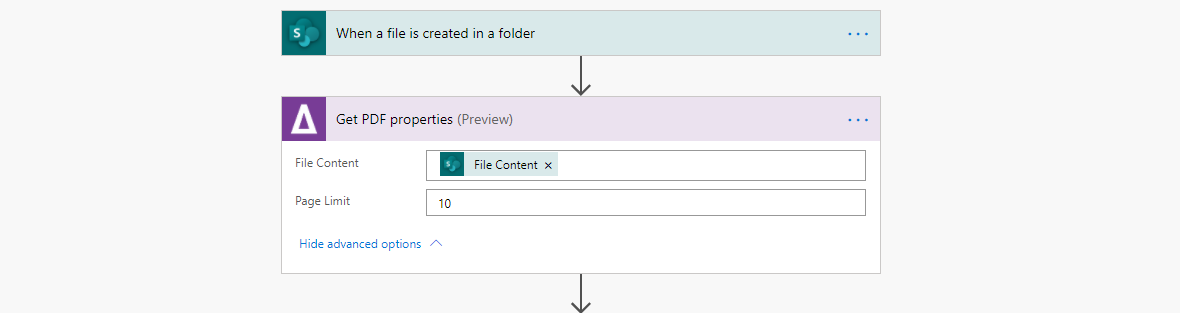
2.) The Aquaforest action ‘OCR PDF or images’ is used to OCR the cover page in the PDF

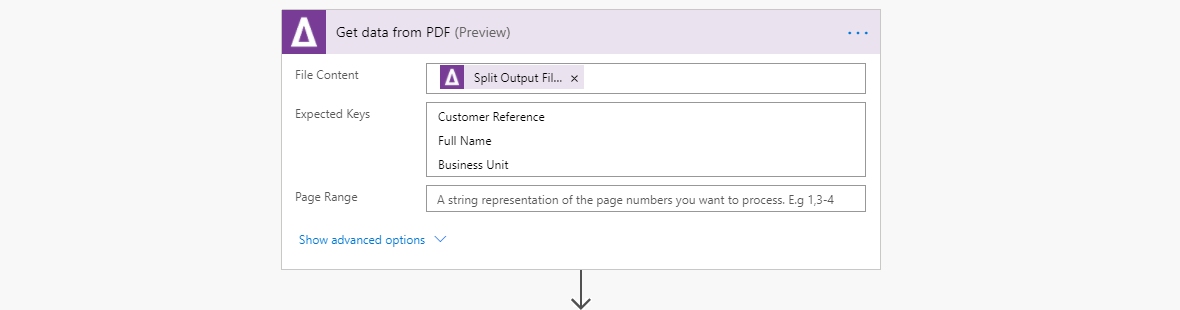
3.) The Aquaforest action ‘Get data from PDF’ is used to retrieve the name-value pairs. That is ‘Customer Reference’, ‘Full Name’ & ‘Business Unit’
4.) The ‘Create item’ action is used to store the extracted data in the SharePoint folder ‘OCR Document Staging’
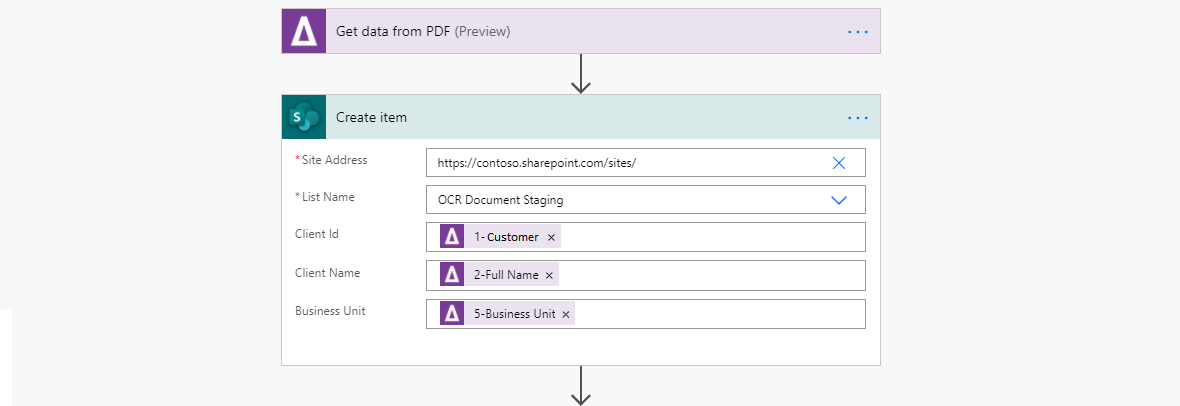

This information that is stored in ‘OCR Document Staging’ could then be uploaded into a system such as Dynamics 365
For more information, please refer to the link: